- システム開発、設計、Web、APP受託開発、ERPソリューション事業
- DX製品の開発、販売、クラウドサービス、人工知能AIモデル・リサーチ事業
- 越境EC、SNS、SEO/SEM、インバウンド、ファイナンス・コンサルティング事業
- ICT技術マーケティング、サーバーPC買取、データ消去、IT機器リサイクル事業

Service
- System development, design, web, APP contract development, ERP solution business
- Development and sales of DX products, cloud services, artificial intelligence AI model research businessartificial intelligence, machine learning, and natural language processing.
- Cross-border EC, SNS, SEO/SEM、inbound, finance consulting business
- ICT technology marketing, server PC purchase, data erasure, IT equipment recycling business

Proudly powered by Tomoki-Tech
TOMOKIはAIモデル構築の基本のアイディアと関連技術
モデル構築の基本アイディア
幾つかの多言語対応のLLM以外、日本語専用のLLMはすくないため、適切なベースモデルを選んで、日本語化のLLMを作りたいです。GPTなどの今流行してるLLMは中小企業にとって大きいすぎるので、事業化するため、新しい手法で再学習する必要があります。ChatGPTなどは、再帰ニューラルネットワーク(RNN)とセルフアテンションメカニズムを基にした生成型言語モデルであり、その構造はモジュラー分割(Modular Decomposition)に適しています。
モジュラー分割は、大規模なニューラルネットワークを複数の独立したモジュールに分割し、各モジュールが特定の機能やタスクを担当するようにします。
一つの関連技術は言語adapterです(モジュラー分割の一つ手法です)。
PEFT、LORAなどの手法はもちろん、さらに高度なモジュラー分割手法を使って、よりいい性能を得ることができます。高度なモジュラー分割のコストは再学習とフールトレーニングの真ん中です。E.g.,6Bモデルの再学習のコストは8万円;フールトレーニングの費用は500万円。モジュラー分割のコストは100万円以内に抑える可能性があります。
なぜモジュラー分割にフォカスする
費用の面もありますが、もう一つ着目する面は解釈性です。博士課程の時から、ずっとモデルの分割を考えていました。下記のようなモデルの構造は簡単にわかります。
AI会社に入った後、その思想を活用して、自動句読点追加モデルなどを開発することにつとめました(深層学習モデルLSTMを導入するために、モデルのアーキテクチャを変更しなければなりません)。
モデルの構造の超疎性のため、今のLLMのモデル分割(主にモジュラー分割)はさらに発展されています。
ChatGPTの構造は再帰ニューラルネットワークに基づいており、セルフアテンションメカニズムを繰り返し適用してシーケンスデータを生成します。そのため、ChatGPTのモデルを複数のサブモジュールに分割し、各サブモジュールが一部の入力シーケンスを処理することができます。
例えば、ChatGPTを以下のようなサブモジュールに分割することができます:
1. 言語エンコーダ(Language Encoder):入力テキストシーケンスをエンコードして表現します。単語埋め込み(Word Embeddings)やセルフアテンションメカニズムを使用して実装することができます。
2. 対話履歴モジュール(Conversation History Module):対話履歴を管理し、対話コンテキストの表現を生成します。
3. 応答生成モジュール(Response Generation Module):現在の対話コンテキストに基づいて次の応答を生成します。セルフアテンションメカニズムやデコーダを使用して実装することができます。
モジュラー分割により、ChatGPTを柔軟に拡張やカスタマイズすることができます。例えば、特定のタスクに対して個別のモジュールのトレーニングを行ったり、異なるデバイス上で異なるモジュールを並列処理したりすることが可能です。また、このような分割はモデルの解釈性やデバッグ能力を向上させ、全体的なモデルの複雑性を低減するのに役立ちます。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
付録:
「MOD-GPT: Modularized Transformer for Large-Scale Language Generation」は、大規模な言語生成モデルGPTの改善を目指したモジュール化に関する研究です。この研究では、GPTを複数の独立したモジュールに分割し、それぞれのモジュールが特定の入力シーケンスを処理する役割を担当します。モジュールの分割と組み合わせにより、モデルの異なる構成要素をより良く理解し、制御することができるだけでなく、モデルの柔軟性と拡張性を向上させることができます。
具体的には、MOD-GPTでは独立したエンコーダとデコーダモジュールが使用され、それらを個別にトレーニングして組み合わせてモデル全体を構築します。エンコーダモジュールは入力シーケンスを中間表現にエンコードし、デコーダモジュールはこれらの中間表現を使用して出力シーケンスを生成します。トレーニングの過程では、各モジュールは独立して最適化や調整が行われ、異なるタスクやデータにより適応することが可能です。
MOD-GPTの主な成果の一つは、大規模な言語生成タスクに対応する拡張性と解釈性のある手法を提供することです。モジュール化の設計により、研究者はモデルの各構成要素をより良く理解し、分析することができ、問題のボトルネックを特定して改善することができます。さらに、MOD-GPTは特定のモジュールの置換や追加により、さまざまな応用シナリオやタスクの要件に適応する柔軟な手法を提供します。
総括すると、MOD-GPTはモジュール化の手法を通じて大規模な言語生成モデルの改善と制御能力を提供します。研究者や開発者にとって、スケーラブルで解釈可能な言語生成システムを構築するためのフレームワークを提供し、自然言語処理タスクのパフォーマンスと効率を向上させるための価値ある手法となります。
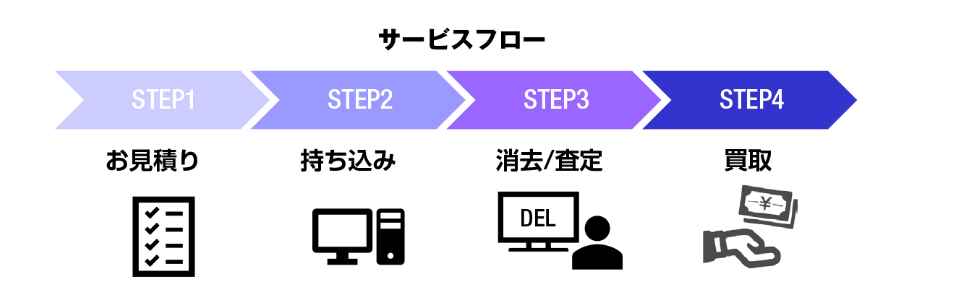
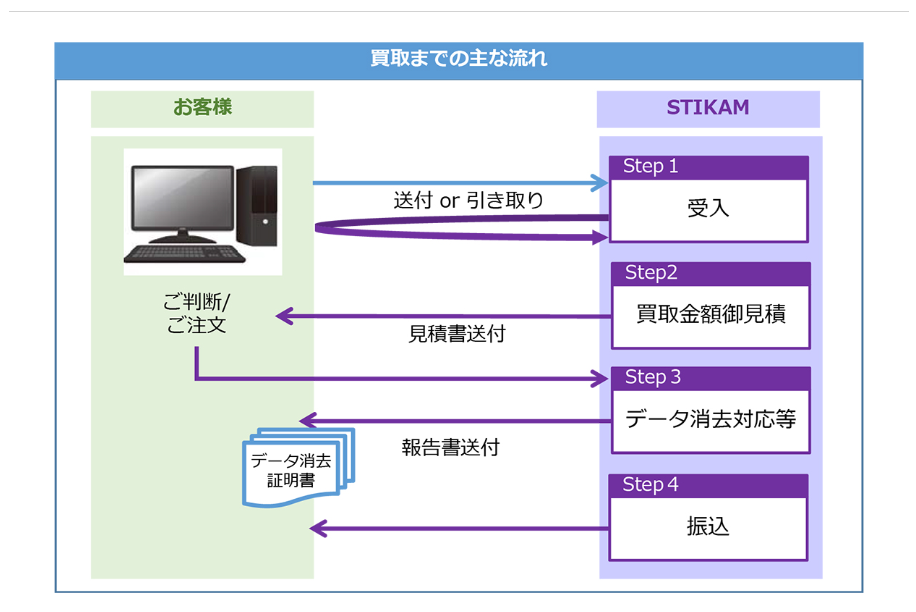
TOMOKI-弊社の機器買取サービスは、日本で全国の廃棄予定のIT機器を有価物として買い取りしますので、廃棄費⽤を掛けずに撤去が可能です。 また、回収から検品、検査、データ消去、買い取りまでの流れを、自社の特定な管理の下に行なっていますので、データ消去についても当社で実施することが可能です。
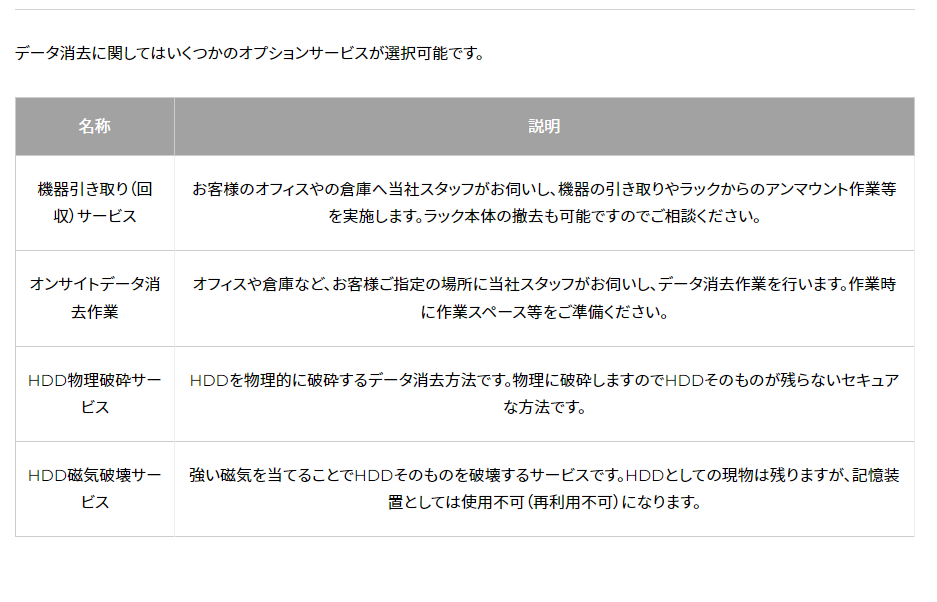
データ消去に関してはいくつかオプションを用意していますので、データ消去の手段/責任分担などを事前にお客様と協議し、ご納得いただける消去サービスを提供してます。
買取までの流れ
データ消去オプションサービス
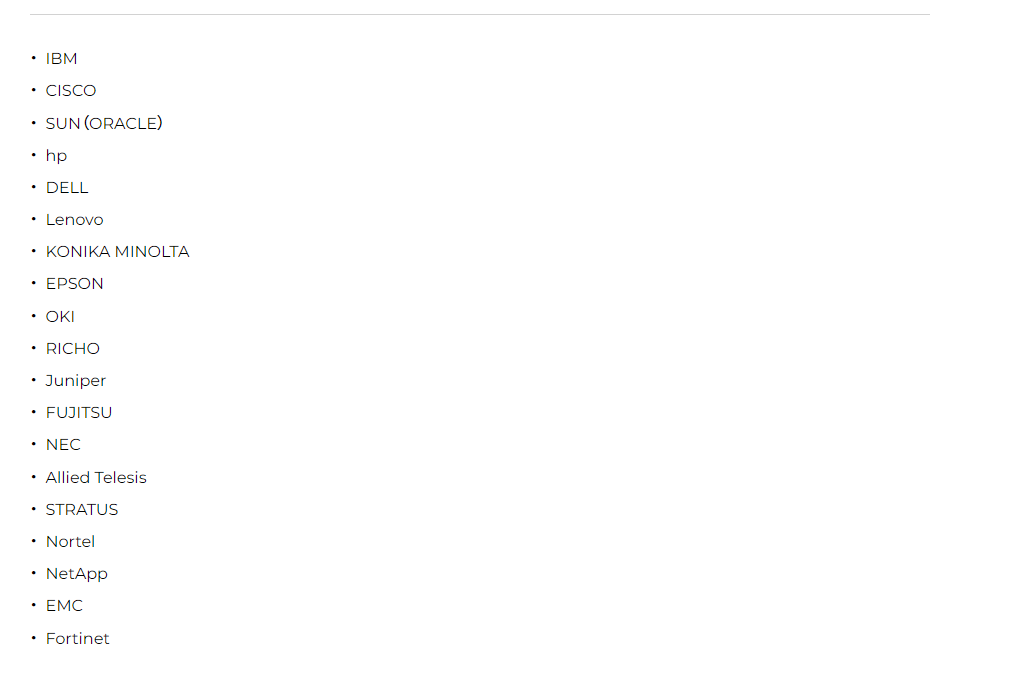
IT機器リユース取扱製品
法人向けのPCリサイクルは、古いコンピュータ機器を環境にやさしい方法で廃棄するプロセスを指します。法人が古いPCをリサイクルすることには、環境保護、データセキュリティ、コスト削減などの利点があります。